InfiniBand 프로그래밍에 필요한 기본 개념
작성일:2014.03.29
수정일:2014.05.11
이 페이지에서는 InfiniBand Verbs 프로그래밍을 시작하기 위해 필요한 기본적인 개념을 설명한다. 본 문서의 정보는RDMA_CM API를 사용하여 프로그래밍하는 경우 도움이된다.
1. 이더넷을 되돌아 보자
InfiniBand를 이야기 하기 전에 현재 네트워크의 주역이 된 이더넷(Ethernet)을 되돌아 보자.
이더넷은 근거리통신망을 구성하기 위한 단말과 네트워크 장치의 규격으로, OSI참조 모델에서는 물리계층과 데이터링크 계층에 해당한다. 시대에 따라 변천이 있었지만, 현재는 단말쪽에 네트워크 인터페이스 카드(Network Interface Card; NIC)를 장착하고,트위스티드 페어 케이블을 사용해 기기를 접속하는 것이 주류이다. 여러 대의NIC는 허브(Hub)로 연결한다.
NIC는48비트 MAC어드레스가 할당되어 있다. 이것은NIC의 제조 단계에서 할당된 고유한 값이며, 기본적으로는 모든NIC는 다른 값을 갖고 있다. 이더넷을 사용한 통신은 자신의 MAC어드레스와 통신하고 싶은 상대의 MAC어드레스를 지정해서 수행하게 된다.
고전적인 이더넷은 전기적으로 연결된 NIC가 서브넷(Subnet)을 구성했다. 하나의NIC가 발생시킨 신호는 전기적으로는 서브넷 내의 모든NIC가 송신 가능했다. 따라서 동시에2개의NIC가 송신하면 신호가 혼선되어 버린다. 이것을 방지하기 위해 이더넷은 CSMA/CD(Carrier Sense Multiple Access/Collision Detection)이라고 불리는 처리를 수행했다.
통신을 개시하려는 NIC는 먼저 서브넷을 감시하고 다른 통신 중인 NIC가 없는 것을 확인한다.
통신로가 비어있다면 자신의 통신을 개시하지만 그 앞에 프리엠블로 불리는8바이트의 더미 정보를 붙인다. 이 프리앰블의 전송 중에 다른 NIC가 동시에 통신을 개시해 충돌하지 않는지 확인한다.
프리앰블 중에 방해받지 않았다면 전송로는 자신이 점유했다고 생각하고 통신을 한다.
자신이 프리앰블을 보내고 있을 때 다른 NIC가 프리앰블을 보내면 '충돌'을 검출하고 통신을 중단한다. 다른NIC도 동일하게 충돌을 검출하고 통신을 중단해야 한다.
충돌검출 후에는 랜덤시간을 기다린 후 다시 프리앰블을 흘려보내는 것으로 통신을 개시한다.
통신로의 점유에 성공해 통신을 시작한 경우, 그 메시지는 자신의 MAC 어드레스와 통신하려는 상대의 MAC 어드레스를 포함해 통신을 수행한다.
전송로를 공유하고 있으므로 통신 내용은 모든 NIC에 전달되지만, 통신 중인 '상대방의 MAC어드레스'와 자신의 MAC 어드레스를 비교해 자신에게 온 것인지 아닌지 판단한다. 자신에게 온 것이 아니라면 내용을 파기한다.
그러나 CSMA/CD는 서브넷의 NIC수를 늘릴 때마다 하나의 NIC가 가능한 통신량이 줄어든다. 그래서 스위치허브(Switch Hub)가 탄생했다. 스위치허브는 자신을 통과하는 패킷의 목적지 MAC 어드레스를 학습하는 것으로 네트워크에 연결되어 있는 NIC가 어느 포트에 연결되어 있는지를 확인한다.
다만 MAC 어드레스는48비트의 어드레스 공간에 어느 정도 흩어져서 존재한다. 스위치허브가 학습할 수 있는 MAC어드레스의 수는 기종마다 차가 있지만 수만~수십만 정도이다. 따라서 해시테이블 등과 같은 복잡한 데이터 구조로 제어가 필요하게 되며, 스위치허브는 수십 마이크로초 정도의 레이턴시를 피할 수 없다.
2. 그렇다면 InfiniBand Architecture 는?
InfiniBand는 이더넷과 동일하게 서버간을 연결하는 고속I/O인커넥터이다.역사적으로는 우여곡절이 있었지만 현재는InfiniBand Trade Association가 관리하고 있다(Wikipedia).
접속 케이블로는 동축(銅軸)및 광섬유가 사용되며, 접속 단자는 QSFP나 CX4가 사용된다. 노드에 꽂는 카드는 Channel Adapter (CA)라고 부른다. CA중에서도 일반 컴퓨터에 꽂는 카드는 Host Channel Adapter (HCA)라고 부른다.그 외에 스토리지 제품에 꽂는 Target Channel Adaptor (TCA)가 있지만, TCA는 HCA의 서브셋이므로 HCA만 고려해도 충분하다.
InfiniBand는 아래와 같은 특징을 갖고 있다.
높은 처리량
주로 사용되는 Quad Data Rate (QDR)에서는 실행 전송 속도가 10 Gbits/초, 최신 Fourteen Data Rate (FDR)에서는 14 Gbits/초가 된다. 이것을 케이블 내에서 4줄로 묶으면 QDR에서는40 Gbits/초, FDR은56 Gbits/초가 실현 될 수 있다. 또한 전이중 통신이므로 송신과 수신을 합하면 QDR은 80 Gbits/초, FDR은 112 Gbits/초가 된다.
짧은 레이턴시
스위치의 레이턴시가 짧다. QDR은 HCA-HCA의 직접 연결1로 100나노초 정도, HCA-Switch-HCA도 1마이크로초 정도의 레이턴시로 통신이 가능하다.
흐름 제어
InfiniBand에는 최소 2종류의 흐름 제어가 존재한다. 한가지는 이더넷에도 존재하는 인접 HCA와 스위치 간, 스위치와 스위치 간에 동작하는 링크레이어의 흐름 제어이다. 다른 한가지는 HCA간에 end-to-end에서 동작하는 흐름 제어로, 양단 버퍼의 빈 용량을 상대방에게 통지하는 것으로 통신량을 조절할 수 있다. 두 종류의 흐름 제어로 폭주에 강한 네트워크를 구성하고, 처리량 한계에 가까운 성능을 쉽게 끌어 낼 수 있다.
Remote Data Memory Access (RDMA)
데이터를 송신처에서 수신처로 전송하는 것 뿐만 아니라, 원격 노드의 메모리 어드레스를 지정해서 데이터를 기록하는 RDMA WRITE나, 원격 노드의 메모리를 읽어오는 RDMA READ 기능이 있다.
제로 카피
InfiniBand는 송신처 프로그램이malloc()이나mmap()으로 확보한 메모리를 수신처 프로그램의 메모리에 직접 전달 할 수 있다. 이 사이에 불필요한 데이터 카피가 발생하지 않기 때문에 낮은 레이턴시가 가능하다.
Software Defined Network
서브넷 내에 있는 노드로 부터 노드로의 패킷 경로는 Subnet Manager로 불리는 콘트롤러가 소프트웨어적으로 제어한다. 루프를 구성하는 부분이 있더라도 옳바른 경로 설정을 하면 동작 시키는 것이 가능하고, 여유도2가 높아 병목현상이 적은 토폴로지를 구성할 수 있다.
3. InfiniBand Fabric
InfiniBand 네트워크는 패브릭(Fabric)이라고 불린다. 패브릭은 '직물'을 의미하며, 이더넷의 스타형 네트워크와 달리 루프를 포함한 결선이 가능하게 되어있다.
HCA와 스위치에는 제조 시에 Globally Unique Identifier (GUID)라고 불리는 식별자가 고유하게 할당된다. 이것은 이더넷의 MAC 어드레스에 대응한다. MAC어드레스가48비트인 반면, InfiniBand의GUID는 64비트이나 큰 차이는 없다. 양쪽 모두 IEEE Registration Authority MA-L에서 관리하고 있다. GUID는 HCA는 포트마다, 스위치는 1개가 할당 된다.
InfiniBand 로컬네트워크는 서브넷(Subnet)이라 불리며, 1개의 서브넷에는 노드 스위치를 합해서 49,151대까지 접속할 수 있다. 복수의 서브넷을 라우터로 연결하는 것도 가능하다. 다만 InfiniBand 규격에는 라우팅 기능은 일부 정의 되어 있지 않고, OSS기반의 라우팅 소프트웨어도 제공되지 않아,일반적으로 사용되지 않는 것 같다.
3.1 LID Routed Network
이더넷의 통신은 MAC 어드레스로 통신 상대를 지정하지만, InfiniBand는 GUID와는 별도로 Local Identifier (LID)로 불리는16비트의 식별자를 할당하고,이것을 사용하여 통신 상대를 지정한다. LID는GUID마다 할당되며, HCA는 포트마다, 스위치에는 1개의LID가 할당된다. 할당 되는 것은0x0001〜0xBFFFF의 유니캐스트용LID이다.
HCA나 스위치는 전원이 끊어지면 자신에게 할당된 LID를 잊어버리므로, 전원을 다시 연결하면다시 재할당할 필요가 있다.
LID의 범위
| 값의 범위 | 의미 |
|---|---|
| 0x0000 | 미할당 |
| 0x0001 ~ 0xBFFF | 유니캐스트 |
| 0xC000 ~ 0xFFFE | 멀티캐스트 |
| 0xFFFF | Permissive DLID |
InfiniBand의 통신이 64비트 GUID를 사용하지 않고 16비트의 LID를 다시 할당하는 것은 통신 지연을 억제하는데 도움이 된다.
48비트의 MAC 어드레스와 64비트의 GUID라면 포트에 출력처를 기록하는 경로 테이블이 해시 테이블처럼 다층의 데이터 구조일 수 밖에 없다.
하지만 16비트 LID의 경우, 유니캐스트 LID는 49,151개 밖에 없으므로, 각 1바이트씩 차지한다고 해도 48KB의 배열이면 충분하다. 멀티캐스트LID도 어떤 포트에서 출력되는지 나타내는 비트맵을 많아야16,383개 가지고 있으면 된다. 32포트 스위치라고 한다면, 1개의 멀티캐스트 LID에 4바이트로64KB의 배열이면 된다.데이터가 적으므로 스위치 내의 CPU 캐시에 충분히 실린다. 따라서 지연이 적어지게 된다.
서브넷을 넘어 다른 노드에 접근하는 경우에는, LID가 아닌 Global Identifier (GID)를 사용한다. GID는128비트로 구성되어 있으며 Ipv6 어드레스와 같은 형식이다. 기본적으로 상위 64비트에 서브넷을 나타내는 ID를, 하위 64비트는 GUID를 넣은 것이 GID가 된다.
다만, InfiniBand 라우팅 기능은 미정의된 부분이 많고, 소프트웨어적으로도 지원하고 있지 않다. 서브넷 내의 노드 간에 LID 대신에 GID를 지정해도 통신할 수 없다.
3.2 구성
서브넷은InfiniBand HCA와 스위치로 구성된다
Host Channel Adaptor(HCA)
HCA는 PCI express에 꽂는 카드이지만, 1포트 혹은 2포트를 가지고 있다. 포트는 0을 제외하고, 포트1, 포트2와 같이 번호가 붙여진다.
멀티 포트 NIC는 기능적으로 분리된 NIC가 한장의 카드에 실린N-in-1이지만,멀티 포트 HCA는 그것과는 다르다. 멀티포트 NIC가 포트마다 독립된 아파트나 맨션이라고 한다면, 멀티포트 HCA는 출구가 2개 있는 단독주택이다. 이것은 InfiniBand 프로그램의 세부사항을 설명하는 단계에서 설명하기로 한다.
그렇다고는 해도, 멀티포트 HCA는 포트마다 별도의 서브넷에 속하는 것이 가능하다. LID는 서브넷 마다 할당되므로, 포트 별로 별도의 서브넷에 속해 있는 경우에는 LID번호가 중복되는 경우가 있다.
InfiniBand규격 상, HCA는 255포트까지 가질 수 있지만, 실제는 2포트를 넘는 것은 존재하지 않는다. OpenFabric이 제공하는 미들웨어도 3포트 이상의 HCA에서 오동작한다.
스위치
InfiniBand 스위치는 물리적인 포트에 포트1, 포트2, 포트3, …과 같이 번호가 매겨진다. 이것 이외에 물리 포트를 가지지 않는 가상 포트가 있으며, 포트0라고 불린다. 포트0는 그다지 의식하지는 않지만, ibnetdiscover 등의 패브릭 확인 툴에는 나타난다.
포트0는 관리용으로 사용된다. 스위치의 GUID는 포트0에 할당 되며, LID도 포트0에 붙여진다. 다른 물리 포트는 GUID를 갖지 않고, LID의 할당도 없다.
InfiniBand 스위치는 하나의 서브넷에 속하는 것만 가능하다. 현재 이더넷 스위치는 VLAN을 잘라 동일한 장비 내에 가상으로 복수의 LAN을 소속 시키는 것이 가능하지만, InfiniBand 스위치에는 유사한 기능이 없다. 다만partition이라 불리는 기능이 있다.
스위치도 255포트까지 가지고 있지만, 판매되는 스위치에는 64포트를 넘는 것은 존재하지 않는다. 1개의 본체에 64포트를 넘는 스위치는 내부에 여러개의 스위치가 들어있는 것일 뿐이다. OpenFabric이 제공하는 미들웨어 역시 64포트를 넘는 스위치에서 오동작 한다.
3.3 Subnet Management
기동시에 HCA포트나 스위치에 LID를 할당하는 일은, Subnet Manager라고 하는 소프트웨어가 담당한다. InfiniBand는 일반적으로 데이터 통신에 사용하는 패킷과는 별도로, 패브릭 운용 관리 등을 목적으로한 관리 패킷이 존재하는데, 그 중에 Directed Route Subnet Management Packet (DrSMP)이있다. Subnet Manager는 DrSMP를 사용해 패브릭의 토폴로지 탐색과 LID할당 등을 수행한다.
Subnet Manager는 HCA의 포트 중 하나, 또는 스위치 내에서 동작하고 ,자신이 기점으로 정한 포트에서 DrSMP를 보낸다. DrSMP에는 InitPath라는 64항목의 배열이 있다. 이 배열에 기점에서 시작하여 어떤 포트에서 출력하는지를 지정하고, 탐색경로를 구성할 수 있다.
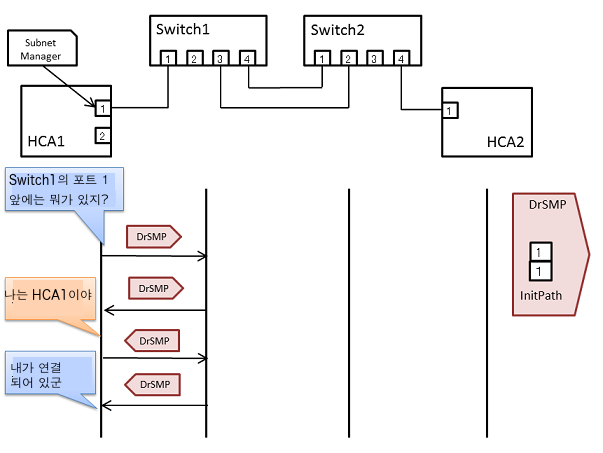
아래의 그림과 같이 스위치2대, HCA 2대의 구성을 생각해 보자. Subnet Manager는HCA 1의 포트 1을 기점으로 한다.
먼저, 포트1의 앞에는 무엇이 있는지를 묻는다. 먼저Switch 1이 발견된다. 실제는 Switch 1이란 이름이 아니라 GUID를 응답한다.
그림에서 DrSMP의 화살표가 오른쪽을 향해 있는 것은 갈 때 InitPath를 참조한다. DrSMP의 화살표가 왼쪽을 향해 있는 것은 올 때, 온 길을 역순으로 추적한다.

다음으로 Switch 1의 포트1의 앞을 찾는다. 이것은 HCA 1로 돌아가는 것이나, DrSMP에는 (Subnet Manager가 아니라) HCA 펌웨어가 응답하고, 자신의 GUID를 대답한다. 역순으로 복귀해서 HCA 1의 포트1로 돌아가면, Subnet Manager에 결과가 전달된다. 그 결과, Switch 1의 포트1의 앞에는 자기 자신이 연결되어 있는 것을 알 수 있다.
탐색이 진행되고 Switch 2를 발견한 후에, Switch 2의 포트1의 앞에 있는 것을 찾는다. Switch 1이 2번째로 발견된다. Subnet Manager는 다른 경로를 거처 Switch 1이 발견된 것이므로, 패브릭 토폴리지가 루프를 구성하고 있는 것을 발견할 수 있다.
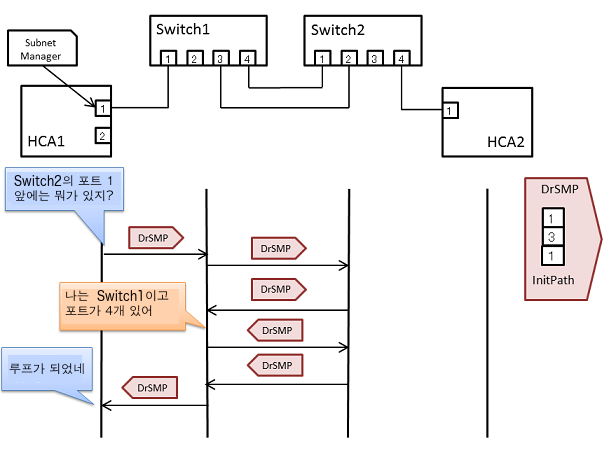
또한, 검색을 진행하면 Switch 2의 포트 4의 앞에 HCA 2를 찾을 수가 있다

이와 같이 DrSMP를 던지는 것으로, 패브릭 내의 모든 HCA와 스위치를 검색하여 GUID를 얻을 수 있다. 패브릭 내의 토폴로지를 분석 후, HCA의 각 포트와 스위치에 LID를 할당하고, 스위치에는 경로 정보(각LID에 어떤 포트에서 출력할 것 인지)를 설정한다.이상의 설정으로InfiniBand패브릭은 운용 가능한 상태가 된다.
Subnet Manager는 LID 할당한 후 운용 단계에서, 패브릭의 일부 구성이 바뀐 경우, 해당 위치를 인식하고 LID를 추가하여 할당하는 처리를 수행한다.
InfiniBand 스위치에는 Subnet Manager 기능을 내장하고 있는 것이 있는데, InfiniBand 지능형 스위치로 불린다. 지능형 스위치는 그렇지 않은 것에 비해 조금 비싸다. 단, Subnet Manager에는 OpenSM이라는 OSS 기능이 있어, 스위치에 지능형이 없더라도 괜찮다.
4. 메모리모델: 제로카피와 RDMA
TCP통신 모델은 소켓마다 통신용과 수신용2개의 가상 링버퍼가 커널 내에 준비 되어있다. 프로그램이send()로 송신 버퍼에 쓰면, NIC는 자동적으로 통신 상대에 데이터를 전송하고, 통신 상대로부터 전송된 데이터는 수신 버퍼에 저장되며, 프로그램이recv()로 그것을 가져오게 된다. UDP는 일대일 통신 모델은 아니지만, 송신,수신 버퍼가 있어sendmsg(), recvmsg()가 있는 점에서는 같다. TCP도 UDP도 전송하고자 하는 데이터나, 수신 데이터를 저장하고자 하는 데이터는 사용자 프로그램 상의 메모리이며, 그것을 일단 커널의 송신, 수신 버퍼에 복사할 필요가 있다.
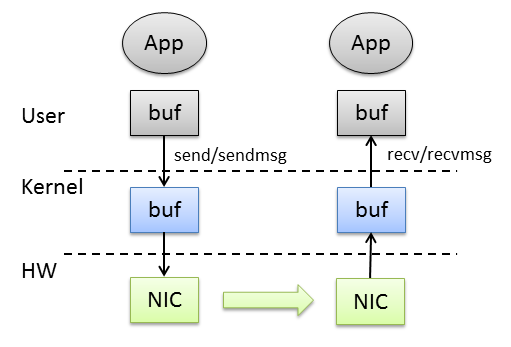
한편, InfiniBand 통신은 제로카피(Zero Copy)를 큰 특징으로 한다. 송신측은 사용자 프로그램이malloc()이나mmap()으로 확보한 메모리를 송신 지정한다. 수신측도 마찬가지 이다.
하지만, 실제 패킷 송수신을 수행하는 것은 HCA이다. HCA는 PCI express 버스를 통해서 물리 메모리어드레스에 DMA 전송하므로, 사용자 프로그램의 가상 메모리어드레스 공간을 이해할 수 없다. InfiniBand 프로그램에서는 데이터를 송수신하기 전에 자신의 프로그램 중 HCA가 액세스 가능한 영역을 Memory Region으로 OS에 등록한다. OS에 등록된 memory region은 가상 메모리 페이지와 물리 메모리 페이지의 관계를 핀으로 고정한다. 따라서 memory region 내의 가상 메모리는 스왑 등으로 디스크로 밀려나는 일이 없어지게 된다.
또한 memory region 등록시에 가상 메모리 페이지와 물리 메모리 페이지의 변환표를 작성하고,그것을 HCA에 전달하여 HCA가 사용자 프로그램의 가상 메모리어드레스 공간의 일부를 인식할 수 있게 된다. HCA는 송신시에도 수신시에도 이 변환표를 참조하여 실제의 DMA 액세스 해야할 물리 메모리 어드레스를 결정할 수 있다. 따라서 호스트의 CPU를 사용하지 않고 데이터 전송이 가능하게 된다.
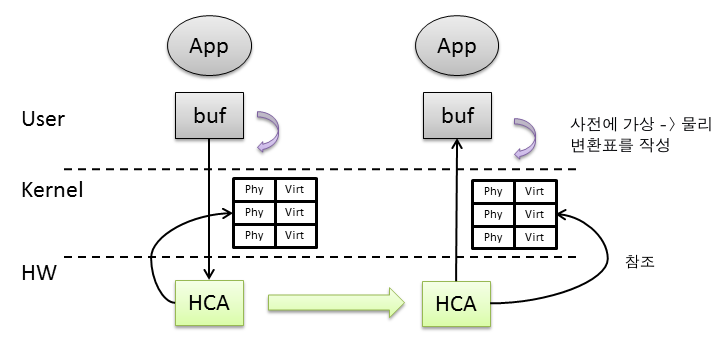
또한 가상 메모리 페이지와 물리 페이지의 변환표 메커니즘을 사용하는 것으로, InfiniBand는 리모트 사용자 프로그램의 어드레스를 직접 지정해서 데이터를 복사하는 Remote Data Memory Address (RDMA)를 실행할 수 있다. RDMA는 리모트 노드에 데이터를 쓰는 것이 RDMA WRITE이며, 리모트 노드에서 데이터를 읽어 들이는 것이 RDMA READ가 된다. 원칙적으로 RDMA는 메모리 노드의 CPU를 일절 통하지 않고, 그 뒷편에서 마음데로 동작한다 (다만, RDMA WRITE는 데이터를 다 쓰고난 타이밍을 통지하는 기능이 있다).
5. 서비스 타입
InfiniBand는 OSI 참조 모델에서 물리계층부터 트랜스포트 계층까지를 일괄 제공하고 있다.
OSI참조 모델에서의 이더넷 & TCP/IP와 InfiniBand의 비교
| OSI참조 모델 | 이더넷 & TCP or UDP/IP | InfiniBand |
|---|---|---|
| 어플리케이션 | ||
| 프리젠테이션 | ||
| 세션 | ||
| 트랜스포트 | TCP or UDP | RC/RD/UD/UC 서비스 |
| 네트워크 | IP | 자세한 내용은 정의되어 있지 않음 |
| 데이타링크 | 이더넷 | InfiniBand 데이터 계층 |
| 물리 | R45J, 무선 등 | QSFP |
InfiniBand 사용자와의 접점이 되는 트랜스포트 계층은 신뢰성 있음(reliable)과 신뢰성 없음(unreliable), 연결(Connection)과 데이터그램(Datagram)으로 구분되어, Reliable Connection (RC), Reliable Datagram (RD), Unreliable Datagram (UD), Unreliable Connection (UC)의 4가지 서비스 유형을 가지고 있다.
Reliable은 데이터 에러시에 자동적으로 재전송하고 리커버리 하는 기능이 있는 서비스이다.
Unreliable에는 리커버리 기능이 없다. 다만 Unreliable이라도 UC는 데이터 손실을 검출하는 기능이 존재한다. UD는 데이터 손실 검출도 스스로 해야 할 필요가 있다.
Connection은 정해진 2개의 QP 사이에서 1대1통신을 한다.
Datagram은 통신 때마다 대상을 지정하고, 여러 QP에 보내고, 여러 QP에서부터 수신 가능하다. 즉,다대다 통신을 한다.
5.1 기본4가지 서비스 유형
4가지 서비스 유형은 정리하자면 다음의 표와 같다.
서비스 타입
| Reliable | Unreliable | |
|---|---|---|
| Connection | RC | UC |
| Datagram | RD | UD |
단, RD는 사용자 영역에 기능이 제공 되지 않으므로, 사용할 수 없다. 또한 UC도 별로 사용되고 있지 않으므로, 일반적으로 RC와 UD가 이용 된다.
| Service Type | Reliable Connection (RC) | Reliable Datagram (RD) | Unreliable Datagram (UD) | Unreliable Connection (UC) |
|---|---|---|---|---|
| Verbs | IBV_QPT_RC | 사용할 수 없음 | IBV_QPT_UD | IBV_QPT_UC |
| 데이터 손실 검출 | Yes | Yes | No | No |
| 에러 리커버리 | Yes 자동 재전송 | Yes 자동 재전송 | No 스스로 할 필요가 있음 | No 스스로 할 필요가 있음 |
| RDMA & ATOMIC operation | Yes | Yes | No | RDMA WRITE계만 지원. RDMA READ계와 ATOMIC은 미지원. |
| 멀티캐스트 지원 | No | No | Yes | No |
| 트랜잭션 지원 | Yes ※1 | No | No | No |
| Shared Receive Queue | Yes | No | Yes | No |
| 메시지 사이즈 | 이론상으로 2^31 바이트. 실제로 기기에 제한이 있음. | 이론상으로 2^31 바이트. 실제로 기기에 제한이 있음. | 최대 4096 바이트 | 이론상 2^31바이트. 실제로 기기에 제한이 있음. |
| TCP/IP와 비교 | TCP | 해당 사항 없음 | UDP | 해당사항 없음 |
※1, 단 Verbs는 트랜잭션 기능 미지원
5.2 그 밖의 패킷
상기 4가지 서비스 이외에 몇 가지 특수한 서비스 패킷이 있다.
제일 중요한 것은 MAD (Management Datagram)이다. 이것은 InfiniBand 패브릭이나 장비 관리를 하기 위한 패킷으로, 여러 이용 용도가 규정되어 있다.
Subnet Management를 위한 Subnet Management Packet (SMP)
Subnet Administration (SA)패킷. SA는 SMP의 보완적 역할을 하고, InfiniBand의 멀티캐스트 등록을 위해 사용 된다.
SM과 SA 이외의 MAD를 General Management Packet (GMP)라고 한다.
성능 정보 교환을 위해 사용하는 Performance Management (PerMgt)
RDMA Communication Manger(CM)가 사용하는Communication Management MAD
Subnet Manager소프트웨어나, Infiniband-diags 패키지에 포함되어 있는 각종 툴을 사용할 때 위의 MAD를 이용하게 된다.
MAD 이외에는 RC를 확장한 eXtensible Reliable Connection (XRC) 서비스 타입, RAW 패킷과 데이터링크 계층의 제어를 수행하는 링크 패킷, 혼잡 제어를 수행하는 Congestion Notification Packet 등이 있다.
6. 기본적인 통신 모델
6.1 Queue Pair(QP)
TCP나 UDP에서는 소켓이 통신의 종단점이었지만, InfiniBand에서는 Queue Pair (QP)가 그 역할을 한다. TCP와 UDP는 하나의 네트워크 인터페이스 내에 각각의 포트 번호(1~65535)에 할당된 소켓을 작성할 수 있었지만, InfiniBand는 이론상 HCA마다 최대 224개의 QP를 만들 수 있다(실제로는 메모리 제한으로 4~7만개 정도 밖에 만들 수 없다).
소켓이 송신 버퍼(send buffer)와 수신 버퍼(receive buffer)를 갖고 있는 것과 같이, QP는 Send Queue (SQ)와 Receive Queue (RQ)를 가지고 있다 (QP의QueuePair라는 명칭은 SQ와 RQ 2가지를 쌍으로 가지고 있는 것에서 유래하였다).
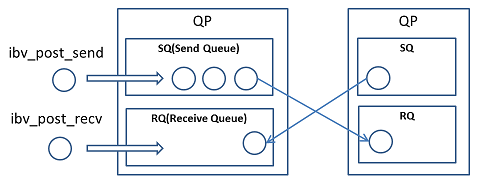
소켓 통신 버퍼와 수신 버퍼는 데이터 자체를 저장하는 링 버퍼이지만, RQ와 SQ는 송신 요구와 수신 요구를 저장하는 First-In Fir-Out (FIFO)이다. 이 요구는 Work Request (WR)이라고 불린다. 송신 요구는 Send WR이며, 수신 요구는 Receive WR이다. 양쪽 모두memory region 내의 메모리 영역이나, 송수신에 관련된 세세한 파라미터를 가지고 있는 구조체 이다. 그리고 Send WR은 ibv_post_send()를 이용해SQ에, Receive WR은 ibv_post_recv()를 이용해 RQ에 쌓는다.
즉, InfiniBand 통신은 Work Request를 하나의 메시지로 전송한다. 바이트 스트림이 무한히 계속 되는 TCP가 아니라, 데이터그램 단위로 보내지는 UDP에 가깝다.다만, InfiniBand의 메시지 최대 사이즈는 규격상으로는 231바이트이다 (실제 기기에는 제한이 있지만, Mellanox의ConnectX-3에는 최대 230바이트로 되어있다).
SQ 또는 RQ에 쌓인 WR은 Work Queue Element (WQE)로 관리 된다. WR도 WQE도 개념적으로는 차이가 없다. InfiniBand규격의 설계자가 그렇게 결정했으므로 일단 이름이 구분되어 있다.
HCA는 SQ의 WQE 정보에 따라 데이터 송신을 시작한다. 이 처리는 사용자 프로그램의 ibv_post_send()를 호출하면 비동기적으로 이루어진다. 수신한 데이터는 RQ의 WQE를 처음부터 꺼내서 그 중에 지정된 메모리 영역에 기록한다. 이 처리도 사용자 프로그램의 ibv_post_recv()도 비동기적으로 이루어진다.
6.2 QP번호 (QPN)
QP번호(QP Number; QPN)는 24비트이기 때문에0x0〜0xFFFFFF까지를 가진다.이 중 0x0와 0xFFFFFF는 특별한 값이다.사용자 프로그램은ibv_create_qp()로QP를 만들지고, 0x2〜0xFFFFFE의 범위의 번호를 부여한다. 단,이 값은 HCA에 의해 자동적으로 할당되며, 자신이 결정할 수 없다. QP번호가 어떤 식으로 부여되는지는 HCA에 달려있다. 현재 주류인 Mellanox HCA의 현재 펌웨어에서는 대부분 랜덤한 값이 된다.
이 동작은 TCP & UDP에서 포트 번호를 0으로 해서bind()를 호출해서 포트 번호 자동할당을 받는 것과 비슷하다. 하지만 TCP & UDP는 프로그램이 포트번호를 정해서, 특정 포트를 할당할 수도 있다. 이것은 SSH이면 TCP/22, HTTP이면 TCP/80 등 서비스를 제공하는 것에 도움이 된다. 하지만 이러한 기능은 InfiniBand에는 없다.
QP번호의 범위
| 값의 범위 | 의미 |
|---|---|
| 0x000000 | QP0 |
| 0x000001 | QP1 |
| 0x000002 ~ 0xFFFFFE | 일반 사용 |
| 0xFFFFFF | 멀티캐스트 용 |
QP0는 특수용도로, 5.2에서 언급한 SMP교환을 위한 전용 QP로 사용된다. 또한 QP1은 SMP 이외의 MAD (SA와GMP)를 교환하기 위한 전용 QP로 사용된다. QP0와 QP1은 IB드라이버 기동시 커널 내에 제일 먼저 확보 되므로, 사용자 프로그램에서 직접 사용할 수 없다.
0xFFFFFF는 멀티캐스트 송신을 위한 전용 QPN이다. 멀티캐스트 메시지를 송신하는 경우, 수신처 QP는 지정할 수 없으므로 대신 0xFFFFFF를 넣도록 되어 있다.
6.3 Completion Queue(CQ)
프로그램은 ibv_post_send()에서 쌓은 Send WR의 완료를 어떻게 알면 좋을까? 또는 자신이 데이터를 수신한 타이밍을 어떻게 알면 좋을까?
InfiniBand는 WR 처리가 끝난 것을 완료(completion)이란 개념으로 인식한다. Send WR이나 Receive WR이 성공으로 처리가 끝난 경우 성공적 완료(Successful Completion)이고, 처리가 에러로 끝난 경우에는 완료 에러(Completion Error)가 된다.
완료는 QP 외부에서 Completion Queue (CQ)로 불리는 데이터 구조에 쌓인다. 이것도 FIFO이다. 송신과 수신 WQE가 처리되는 경우는, 각각 설정된 CQ에 Completion Queue Entry (CQE)가 쌓인다. WQE가 Element로, CQE는 Entry인 것은 틀림이 없다. InfiniBand규격에 그렇게 쓰여 있다.
원칙적으로, 1개의 WQE에 대해 CQE는1개가 쌓인다. 사용자는CQ에 ibv_poll_cq()를 사용하므로서, 쌓인 CQE를 꺼낼 수 있다. 이것이 WR을 처리한 결과가 된다.
꺼내진 CQE는 또 다시 이름이 바뀌어 Work Completion (WC)로 불린다. CQE도 WE도 개념적으로는 거의 차이가 없다. 명칭적 혼란은 InfiniBand규격의 특징이다.
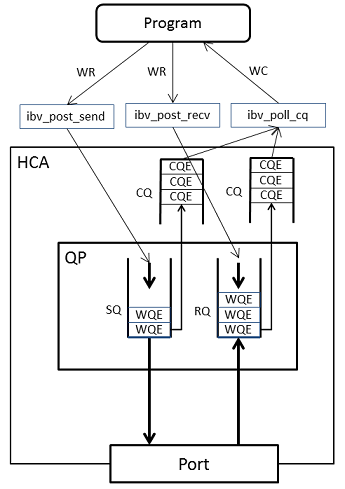
프로그램이 정기적으로 ibv_poll_cq()을실행해서 완료를 기다리는 것 이외에, 8.1에서 언급할 completion channel을 사용해서 완료를 인터럽트로 감지하는 방법이 있다.
6.4 QP와 CQ의 조합
QP는 만들 때CQ를 설정한다.
CQ는 QP로부터 독립적이고, 송신 CQ와 수신 CQ는 별도로 설정할 수 있다.
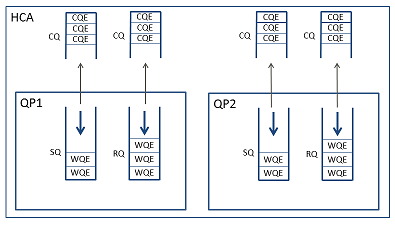
물론 QP 내의 송신 CQ와 수신 CQ가 동일한 것이어도 좋다. QP사이에서 CQ를 공유하는 것도 가능하다.
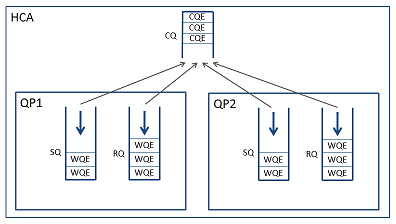
WC 내에는 자신이 어느 QP의 완료인지를 나타내는 정보가 들어 있다. 하지만 WC 내에는 자신이 송신에서 발생한 완료인지, 수신에서 발생한 완료인지를 정확히 구별하는 정보가 들어있지 않다 (뒤에 설명할 wr_id를 사용하는 방법을 별도로 한다). 따라서, 개인적으로는 송신 CQ와 수신 CQ는 나누는 것을 추천한다.
6.5 Work Request와 Work Completion 데이터 구조
SQ와 RQ에 쌓여있는 Work Request를 좀 더 자세히 살펴본다.
먼저 Send WR이나 Receive WR은 아래와 같은 데이터 구조를 가진다 (이번 설명에 필요한 부분의 발췌이다).
Work Request를 나타내는 데이터 구조체(struct ibv_send_wr, struct ibv_recv_wr)의 발췌
| 필드명 | 타입 | 설명 |
|---|---|---|
| wr_id | uint64_t | 프로그램이 임의의 값을 포함할 수 있는 필드 |
| sg_list | struct ibv_sge* | Scatter/gather 리스트 배열로의 포인터 |
| num_sge | int | Scatter/gather리스트 배열의 구송요소 수 |
| opcode | ibv_wr_opcode | Send WR에만 존재하며, 추후 설명할 통신 방법의 종류를 지정한다. |
| imm_data | uint32_t | Send WR에만 존재하며, 추후 설명할 통신 방법의 일부에서 이용된다. |
WR의 버퍼는 sg_list와 num_sge를 사용해 Scatter/Gather리스트로 지정한다. S/G리스트는 memory region 내의 연속한 영역을 하나의 S/G항목으로 하고,그 S/G 항목을 여러개 늘어놓을 수 있다. 따라서 사용자 프로그램 내에서 연속되지 않은 메모리 영역을 한번에 송신하거나, 역으로 연속되지 않은 메모리 영역에 데이터를 수신하는 것이 복사 없이 가능하다.
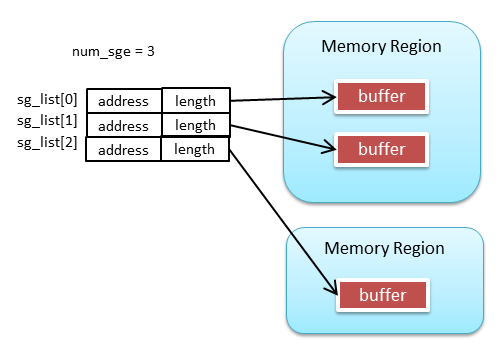
한편, Work Completion은 아래와 같은 데이터 구조이다.
Work Completion을 나타내는 데이터 구조체(struct ibv_wc)의 발췌
| 필드명 | 타입 | 설명 |
|---|---|---|
| wr_id | uint64_t | WR의 wr_id가 복사 된다. |
| status | enum ibv_wc_status | 완료가 성공인지 에러인지. 에러인 경우에는 에러 유형도 보고. |
| opcode | enum ibv_wc_opcode | WR의 통신 방식의 종류를 보고. 단, 에러시에는 믿을 수 없다. |
| byte_len | byte_len | Receive WR에 대한 완료가 성공한 경우, 전송한 데이터 크기가 들어간다. |
| imm_data | uint32_t | 추후에 설명할 통신 방식의 일부에서 이용된다. |
| qp_num | uint32_t | WR이 소속되어 있는 QP를 QP번호로 보고한다. |
Send WR또는Receive WR에wr_id를 넣은 값은WC의wr_id로 꺼내지므로,이것을 사용해SQ, RQ에 투입한 버퍼의 관리할 수 있다.wr_id는 임의의64비트 값을 넣으므로,현재 주류의64비트 커넥터라면 포인터 자체를 저장할 수 있고, 64비트를 적당한 비트로 잘라 의미를 부여할 수도 있다.
6.6 QP는 몇개 필요한가?
InfiniBand 프로그램에서는 프로세스마다 HCA를 이용한다. 따라서, 호스트 내의 여러개의 프로세스가 있다면 각각 개별 QP가 필요하게 된다.
UD 서비스에서 QP는 다대다 통신이 가능하므로, 기본적으로 각 프로세스에 1개의 QP를 만들면 통신할 수 있다.
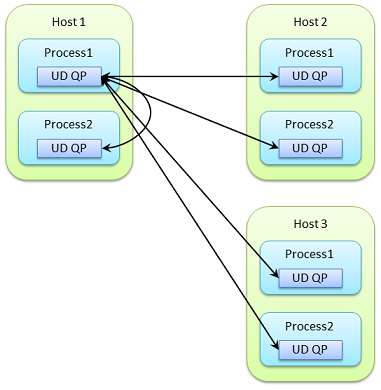
한편, RC 서비스에서 QP는 1대1통신이다. 각 프로세스에 통신 상대 프로세스의 개수 만큼의 QP를 만들 필요가 있다.
아래 그림에서는 Host1의 Process1만이 5개의 QP를 갖고 다른 프로세스와 통신하지만, 각 프로세스가 다른 전체 프로세스와 완전 메쉬3로 액세스하려는 경우에는 모두 30개의 QP가 필요하다. 통신 상대가 증가하면 QP는 더 많아진다. 일반적으로는 노드 수 N과 노드 당 프로세스 수 P에 대해 N ×P×P의 QP가 필요하게 된다.
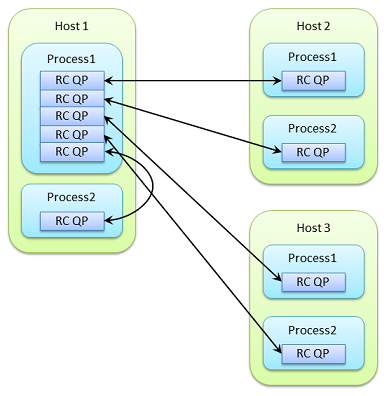
RC 서비스를 사용했기 때문에 QP 자원의 대량 소비를 억제하기 위해, RC 서비스를 확장한 XRC 서비스가 있다. 상세한 사항은 이후에 집필할 별도의 기사에서 설명한다.
6.7 언제 송신이 완료 되는가?
송신 완료는 reliable 서비스인지 unreliable 서비스인지에 의해 달라진다.
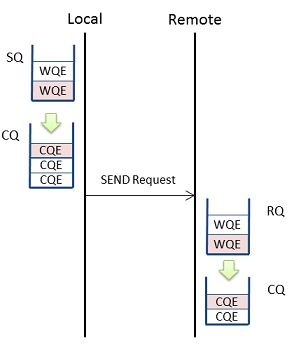
Unreliable 서비스인 UD의 경우, HCA가 Send WQE를 꺼내 그것을 패브릭에 던지면 완료된다. 그대로 송신 CQ에 CQE가 쌓인다. 데이터가 수신측에 도착하는지는 확인하지 않는다.
Reliable 서비스인 RC의 경우, 리모트에서 ACK가 도착하고, 그것을 로컬 HCA가 수신한 시점에 완료가 된다. ACK을 받지 못한 경우, 일정 규칙에 따라 로컬에서 재전송을 반복한다. 재전송을 반복하여 한계에 도달한 경우, 타임아웃이 발생한다.이 경우, 로컬은 완료에러로 송신 CQ에 CQE를 쌓는다.
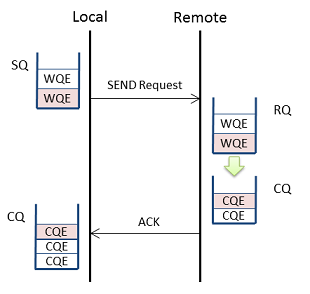
RC가 타임아웃하는 패턴은 2종류가 있다. 한가지는 패브릭에 장애가 발생하고, 통신 불능이된 경우이다. 이것은 알기 쉽다.
또 한가지는 리모트가 RQ에 쌓아야 하는 WQE를 끊어버린 경우이다. 이 경우, 리모트는 수신준비가 완료되지 않은 RNR(Receiver Not Ready)라는 상태의 Negative ACK (NAK)를 로컬에 돌려준다. RNR NAK를 받은 로컬은 일정 시간을 두고 재전송하지만, 규정 횟수의 재전송이 실패한 경우에는 타임아웃 한다.
TCP의 경우에는 수신측이 ibv_post_recv()를 실행하지 않기 때문에, 수신 버퍼가 넘치는 경우가 있어도, 네트워크에 연결되어 있다면, 송신측은 계속 기다려 준다. 하지만 InfiniBand에서는 네트워크가 완전한 상태라도, 리모트가 빨리 처리하지 않으면, 타임아웃 에러가 될 수 있다.
재전송 제어의 상세한 사항은 「InfiniBand의 재전송제어 이해하기」에서 설명한다.
6.8 Shared Receive Queue
앞에서 설명 한 바와 같이 InfiniBand는 RQ에 방심없이 Receive WR을 계속 투입하지 않으면 에러가 발생할 수 있는 엄격한 규격이다. 많은 수의 QP가 있을 때에 적은 수의 QP에 집중해서 부하가 발생하면, 타임아웃 될 위험성이 있다.
그래서 Shared Receive Queue (SRQ)가 등장한다. QP가 SRQ를 설정하면, 자신의 RQ가 무효화되고, 데이터 수신시에 SRQ에서 Receive WQE를 꺼낼 수 있게 된다. 프로그램은 개별QP의 RQ가 아니라, 공통 SRQ에만 Receive WR를 투입하면 된다. SRQ로의 Receive WR의 투입은 ibv_post_recv()가 아니라 ibv_post_srq_recv()를 사용하지만, 그 이외에는 거의 동일하다.
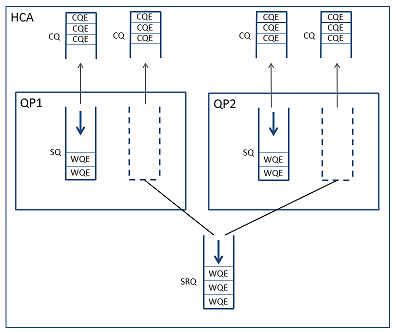
QP는 Queue Pair 이어야 하지만, SRQ를 사용하면 SQ밖에 없기 때문에 이름이 이상하다고 느껴지지만, DVD가 digital versatile disc에서 단지DVD라는 3글자 단어가 된 것 처럼, 지금은 QP라는 단2글자 단어가 있다고 해석해야 한다.
7. 오퍼레이션의 종류
6.기본적인 통신모델에서는 InfiniBand의 기본적인 통신 모델을 설명했지만, InfiniBand 통신에는 SEND, RDMA WRITE, RDMA WRITE with Immediate, RDMA READ, ATOMIC Operation 등 여러 종류의 오퍼레이션들이 존재한다.
단, 서비스에 따라 사용가능한 오퍼레이션이 있다. RC는 모든 오퍼레이션을 사용할 수 있지만, UD는 Send-Receive 오퍼레이션만 가능하다.
서비스별 사용가능한 오퍼레이션 종류
| 오퍼레이션 | UD | UC | RC |
|---|---|---|---|
| SEND | OK | OK | OK |
| RDMA WRITE | OK | OK | |
| RDMA WRITE w/Imm | OK | OK | |
| RDMA READ | OK | ||
| Automic Operation | OK |
7.1 SEND
SEND 오퍼레이션은 지금까지 설명해 온 송수신의 기본 모델이다. 로컬이 리모트로 데이터를 전송한다.
로컬은 ibv_post_send()로 보내고 싶은 데이터의 메모리 영역을 지정한다.
리모트는 ibv_post_recv()로, SRQ를 사용한 경우에는 ibv_post_srq_recv()로 데이터를 수신하고 싶은 메모리 영역을 지정한다.
수신이 성공한 경우, 리모트의 수신 CQ에 완료가 쌓인다.
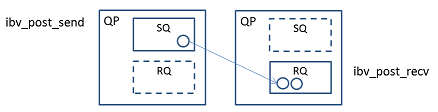
SEND 오퍼레이션은, 전송해야 할 데이터와는 별도로 32비트의 정수값을 전송할 수 있다. 6.5 Work Request와Work Completion의 데이터 구조에서 설명한 로컬 Send WR의 imm_data를 사용해 지정하고, 수신 CQ의 WC 내에 imm_data로 받을 수 있다.
또한 메모리 값을 보내지 않는 SEND 오퍼레이션은 보통 SEND, 메모리 값을 보내는 SEND 오퍼레이션은 SEND with Immediate로 구별해 부르는 것도 있다.
7.2 RDMA WRITE
RDMA WRITE 오퍼레이션은 제2의 모델이다. 이것도 로컬이 리모트에 데이터를 보내는 모델이다.
로컬은 ibv_post_send()로 송신하고 싶은 데이터의 메모리 영역을 지정한다. 또한, Send WR 내에 쓰고 싶은 리모트 메모리의 메모리 영역의 리모트 메모리 어드레스와 길이를 설정한다.
리모트는 RQ 또는 SRQ를 소비하지 않는다. 따라서 ibv_post_recv() 나 ibv_post_srq_recv()를 부를 필요가 없다.
수신이 성공한 경우, 리모트는 알아채지 못한다. 수신이 실패한 경우에 리모트는 비동기 에러가 발생한다.
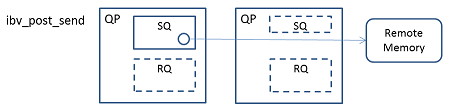
로컬은 scatter/gather를 사용할 수 있지만, 리모트 메모리 영역은 연속 된 단일 메모리 영역이 된다.
7.3 RDMA WRITE with Immediate
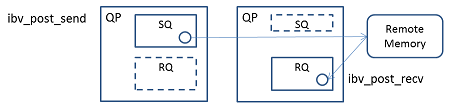
RDMA WRITE with Immediate오퍼레이션은 제3의 모델이다.이것도 로컬이 리모트에 데이터를 전송하는 모델이다.
RDMA WRITE 오퍼레이션은 리모트로 보자면 자신의 메모리가 다시 쓰여졌는데 자신은 감지하지 못하는 것이다. 이것만으로는 부족하므로, 수신완료를 받은 RDMA WRITE로 SEND with Immediate 오퍼레이션과 같이 32비트 값을 보낼 수 있다.
로컬은 ibv_post_send()로 송신하고 싶은 메모리 영역을 지정한다. 또한 Send WR 내에 쓰고 싶은 리모트의 메모리 영역을 리모트 메모리 어드레스와 길이로 지정한다. Send WR의imm_data에 32 비트값을 설정한다.
리모트는 ibv_post_recv()에서 SQR을 사용하는 경우, ibv_post_srq_recv()에 Receive WR을 쌓는다. 단, Receive WR의 메모리 영역(sg_list나num_sge)은 사용되지 않는다. 쓰는 것은 어디까지나 로컬이 지정한 리모트 메모리 어드레스에서 수행된다.
수신이 성공한 경우, 리모트의 수신 CQ에 완료가 쌓인다. 이 WC의 imm_data 내에 송신측이 보낸 32비트 값이 들어있다.
수신이 실패한 경우, 리모트 의 수신 CQ에 완료 에러가 올라오는 경우와, 비동기 에러가 올라오는 경우, 모두 있을 수 있다.
SEND 오퍼레이션과 SEND with Immediate 오퍼레이션은 거의 동등한 모델이었지만, RDMA WRITE 오퍼레이션과 WDMA WRITE with Immediate 오퍼레이션은 프로그램적으로 완전히 다른 모델이라는 점에서 주의가 필요하다.
완료가 올라가는 것에서, 리모트는 자신의 메모리가 다시 쓰여진 것을 감지할 수 있게 된다. 그렇다면 리모트는 자신의 어떤 메모리 어드레스가 다시 쓰여졌는지 알 수 있는가?
알 수 없다. imm_data 값을 프 로그램에서 고려하여 로컬과 리모트에서 표시4를 맞추는 수 밖에 없다.
7.4 RDMA READ
RDMA READ 오퍼레이션은 제 4의 모델이다. 지금까지와는 반대로 리모트에서 로컬로 데이터를 보내는 모델이다.
로컬은 ibv_post_send()로 데이터를 수신할 리모트 영역을 지정한다. 또한, Send WR 내에 쓰고 싶은 리모트의 메모리 영역을 리모트 메모리 어드레스와 길이로 지정한다.
리모트는 RQ 또는SRQ를 소비하지 않는다. 따라서 ibv_post_recv() 나 ibv_post_srq_recv()를 호출할 필요가 없다.
성공한 경우, 리모트는 알아채지 못한다. 실패한 경우는 리모트는 비동기 에러가 올라간다.
성공한 경우, 로컬의 Send WR에서 지정한 메모리 영역에 데이터가 쓰여진다.
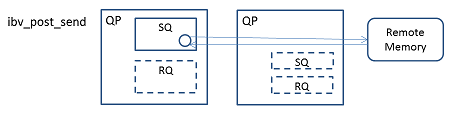
로컬은 scatter/gather을 사용할 수 있지만, 리모트의 메모리 영역은 연속된 단일 메모리 영역이 된다.
지금까지의 모델은 Send WR의 sg_list, num_sge이 송신하는 메모리 영역을 지정하고 있었지만, RDMA READ 오퍼레이션은 Send WR로 수신한 메모리 영역을 지정하는 점이 중요하다. 로컬에 Receive WR을 쌓고 있다고 해도, 그것은 사용되지 않는다.
무엇이 Send WR이고 무엇이 Receive WR 인지 헤깔리는 규격이지만, 명칭의 혼란을 신경 쓴다면 InfiniBand를 이해할 수 없다.
7.5 ATOMIC Operations
ATOMIC 오퍼레이션은, Fetch and Add 오퍼레이션과 Compare and Swap 오퍼레이션 두가지 이다. 모두 리모트의 메모리에 원자성작업을 수행하고, 그 결과 이전의 리모트 메모리 내용을 로컬로 되돌리는 일련의 작업을 수행한다.
Compare and Swap 오퍼레이션은 리모트 '메모리 어드레스', '현재값', '변경값' 3가지를 보낸다. 리모트는 '메모리 어드레스' 내용을 '현재값'과 비교해서 일치하면 '변경값'을 원자적으로 변경한다.
Fetch and Add 오퍼레이션은 리모트의 '메모리 어드레스', '증분' 2가지를 보낸다. 리모트는 '메모리 어드레스'의 내용에 원자적으로 '증분'을 더한다.
조작할 수 있는 것은 리모트의 8바이트 경계에 따른 8바이트 메모리가 대상이다. 1/2/4바이트 조작은 준비되어 있지 않다. 또, 리모트는 그 머신의 네이티브 엔디안에 따라 처리한다. Little endian의 x86-64와 big endian의 SPARC에서는 결과가 다른 점에 주의할 필요가 있다.
ATOMIC 오퍼레이션은 리모트의 변경 전의 메모리 내용(8바이트)을 로컬에 전송한다. Compare and Swap 오퍼에이션은 지정한 '현재값'과 전송 내용이 일치하는지를 비교해서 Compare and Swap의 여부를 체크할 수 있다. Fetch and Add 오퍼레이션의 경우도 자신이 변경하기 전의 리모트 메모리 내용을 확인할 수 있다.
로컬은 ibv_post_send()으로 데이터를 수신할 메모리 영역을 지정한다. 또한 Send WR내에 쓰고 싶은 원격 메모리 어드레스와 Fetch and Add, Compare and Swap 고유의 파라미터를 보낸다.
리모트는 RQ 또는 SRQ를 소비하지 않는다. 따라서 ibv_post_recv() 나 ibv_post_srq_recv()를 부를 필요가 없다.
성공한 경우, 리모트는 알아챌 수 없다. 실패한 경우는, 리모트는 비동기 에러가 올라간다.
성공한 경우, 로컬의 Send WR에 지정한 메모리 영역에 데이터가 쓰여진다.
리모트의 메모리 영역은 연속된 단일 메모리 영역(8바이트)이 된다. 로컬은 scatter/gather를 사용할 수 있다. 단, 쓴 데이터 길이는 8바이트 고정이므로, scatter/gather을 사용하는 메리트는 없다.
8. 완료 대기 모델
6.3에서는 송신이나 수신 완료는 ibv_poll_cq()를 사용하여 CQ를 체크하는 것으로 수행된다고 썼으나, 이것은 일반적으로 폴링(polling)이라 불리우는 방식으로, 완료를 기다리고 있는 동안에도 CPU 파워를 낭비한다.
폴링방식과는 별도로, 다른 스레드에게 CPU 사용권을 대기리스트에 넣고, 완료 이벤트가 발생한 시점에 깨어나는 인터럽트 방식이 존재한다. 여기에는Completion Channel을 사용한다.
8.1 Completion Channel
Completion channel은 ibv_create_comp_channel()로 만들어진다. CQ는 ibv_create_cq()로 작성할 때는 이미 존재하고 있는 completion channel을 한개 지정할 수 있다. 일대다 관계이므로, 여러 개의 CQ를 단일 completion channel에 할당하는 것도 가능하다.
Completion channel은 ibv_get_cq_event()를 호출하면, 완료 이벤트가 발생한 CQ를 불러 낼 수 있다. 완료 이벤트가 발생하지 않은 CQ가 없는 경우, 자신이 관리하고 있는 CQ 중 어느 하나에 완료 이벤트가 발생할 때 까지 커널 내에 대기하게 된다.
Completion channel에는 조금 더 기교적인 사용 방법이 있는데,select()나poll()으로 기다릴 수 있다. 이것은 API 해설에서 설명하기로 한다.
8.2 Completion Vector
Completion channel을 사용한 완료 이벤트의 실체는 HCA가 발생시킨 MSI-X 인터럽트이다. 따라서, 성능을 추구한다면, InfiniBand의 완료를 통지하는 MSI-X 인터럽트는 완료를 담당하는 completion channel을 ibv_get_cq_event()하고 있는 스레드의 논리 CPU에서 움직이고 싶어한다.
그래서 IB 디바이스는 임의의 논리 CPU에서 MSI-X 인터럽트를 발생시키기 위해서, 가능하다면 시스템의 논리 CPU 수 이상의 IRQ를 사전에 준비한다. 이것을 InfiniBand 프로그램에서는 Completion Vector라는 표현으로 부른다.
예를들어, Mellanox HCA에서 mlx4 드라이버를 동작시키면, /proc/interrupts 아래에는 다음과 같은 행이 나타난다.
커널에는 eth-mlx4-N 이라는 이름의 IRQ가 확보된다. N에는 0부터 시작하는 CPU 번호가 들어있다.
예를들어, 논리 CPU가 16개 있다면, eth-mlx4-0〜eth-mlx4-15으로 16개의 IRQ가 생긴다.
RHEL6 커널에는, 먼저 mlx4-comp-N@pci:xxxx:xx:xx.x가 확보된다. N에는 0~2가 들어있다. 다음으로 mlx4-ib-C-N@PCI Bus xxxx:xx 이름의 IRQ가 확보된다. C에는 1부터 시작하는 CPU 소켓 번호가, N에는 0부터 시작하는 CPU소켓 내의 논리 CPU 번호가 들어간다.
에를들어, 8코어 CPU를 2소켓 장착하면, 아래의 3+16개의 IRQ가 생긴다.mlx4-comp-N@pci:xxxx:xx:xx.x
mlx4-ib-1-0@PCI Bus xxxx:xx〜mlx4-ib-1-7@PCI Bus xxxx:xx
mlx4-ib-2-0@PCI Bus xxxx:xx〜mlx4-ib-2-7@PCI Bus xxxx:xx
ibv_create_cq()의 5번째 인수는, 이 IRQ 중 어디에 인터럽트를 발생 시킬지를 지정할 수 있다 (몇 번 comp_vector가 어느 IRQ에 대응하는지는 매뉴얼화 되어있지 않기 때문에 실제 장비에서 조사가 필요하다). 사전에 /proc/irq/*/smp_affinity를 설정하고 completion vector와I/O affinity를 조정하는 것으로, 프로그램 내에서 인터럽트 발생 위치를 컨트롤하는 것이 가능하다.
Completion channel의 실제 사용방법은 ibv_create_cq()를 설명하는 것으로 한다.
9. 비동기 에러
InfiniBand Verbs는 비동기 에러(asynchronous error) 또는 비동기 이벤트(asynchronous event) 메커니즘을 가지고 있다. 통신 에러는 CQ를 사용한 완료 에러에 보고되지만, 완료를 되돌려주지 않는 오퍼레이션 통신 에러나, 포트의 Link-Up/Link-Down, 치명적인 고장 등은 비동기 에러로 반환된다.
프로그램에서는 ibv_get_async_event()를 호출하는 것으로 비동기 에러(이벤트)를 얻을 수 있다. 또한 비동기 에러(이벤트)의 도착을select()나poll()로 기다릴 수 있다.
10. 멀티캐스트
InfiniBand는 멀티캐스트 통신도 지원한다. 단, 멀티캐스트가 사용되는 것은 서비스 타입 중에 UD뿐이다. RC/RD/UC에서는 멀티케스트를 이용할 수 없다.
InfiniBand에는 서브넷 내에 닫혀 있는 멀티캐스트가 정의 되어 있고, LID 중 멀티캐스트용 0xC000〜0xFFFE에 할당된 값을 이용해서 통신한다. 스위치는 멀티캐스트 포워딩 테이블에 따라 멀티캐스트의 도착지에 IB 패킷을 복제해 보낸다.
멀티캐스트에 참가하고 싶은 노드는 Subnet Manager에 자신을 등록하고, Subnet Manager에 각 스위치의 멀티태스크 포워딩 테이블을 변경해 달라고 할 필요가 있다. 등록 의뢰는5.2에서 설명한 Subnet Administration의 MCMemberRecord 라는 MAD 패킷을 Subnet Manager가 실행되고 있는 LID에 송신하는 것이 된다(슬프게도 MAD 송신은 InfiniBand Verbs 프로그램의 틀을 조금 벗어 있어, InfiniBand Verbs 프로그램만으로는 자유롭게 멀티태스크를 사용할 수 없다).
멀티태스크 송신측은 LID를 지정하지만, 송신처의 QP까지는 지정할 수 없다. 수신 QP가 정해져 있지 않기 때문이다. 따라서 송신측은 QP 번호를 0xFFFFFF로 설정해서 송신한다. 각 노드에서 멀티태스크의 수신지가 되고 싶은 QP는 ibv_attach_mcast()를 사용해 자신을 등록한다. 멀티태스크를 수신한 HCA는 패킷을 복제해서 등록된 QP 모두에게 전달된다 (동일한 멀티태스크 LID에 대해, 등록 가능한 QP의 수는 하드웨어 고유한 상한이 있다). 하나의 HCA 내의 멀티태스크 LID에 여러개의 QP가 설정되어 있는 경우, 그 중 하나의 QP가 멀티태스크 메시지를 송신하면 루프백 동작해서 등록한 다른 모든 QP에 도착한다. 단, 멀티태스크 메시지를 송신한 QP 자신에게는 도착하지 않는다.
멀티태스크는 서브넷의 준비만 갖추어진다면, 사용자 프로그램에서 ibv_post_send()를 사용해 송신할 수 있다.
InfiniBand에는 서브넷을 넘는 멀티태스크도 예상하고 있어서 멀티태스크 GID를 사용한다. 그러나 상세한 규격은 정의되어 있지 않으므로, 현재로서는 사용하기 힘들다.
11. 전송제어와 혼잡제어
5.에서 언급한 것처럼 InfiniBand의 신뢰할 수 있는 서비스에는 전송 제어가 이루어진다. 또한 2.에서 설명한 바와 같이 혼잡 제어도 수행된다. 이 메커니즘에 대해 설명한다.
하지만 그 전에 TCP의 재전송, 혼잡제어를 생각해 보자.
11.1 TCP를 되돌아 보자
TCP는 송신측의 소켓에서 수신측의 소켓에 전달되는 바이트 스트림으로, 송신측과 수신측이 어떤 바이트까지 보내고 받을지를 Packet Sequence Number (PSN)로 관리하고 있다. 송신측의 패킷에는 PSN이 포함되어 있고, 수신측에서 수신 확인 할 수 있는 위치를 PSN으로 반환한다. PSN은 32비트 크기로 4GB의 데이터를 표현할 수 있다.
PSN 이외에 아래와 같은 메커니즘이 있다.
슬라이딩윈도우 (Sliding window)
송신측이 한번에 송신할 양, 또는 수신측이 한번에 수신할 수 있는 양은 슬라이딩 윈도우에서 조정하고 있다. 이 슬라이딩 윈도우 값은 송신이 성공하면 늘어나고, 실패하면 줄어드는 것으로 혼잡제어를 수행한다. 슬라이딩 윈도우의 최대 사이즈는 보통 65,536 바이트, TCP Window Scale Option (WSopt)을 사용한 경우 216+14 바이트 (1GB)가 된다.
Coalescing ACK
TCP는 송신 패킷 하나하나에 ACK를 반환할 필요가 없고, 최후에 수신한 PSN 의 ACK 를 반환하면 그 이전의 ACK를 한데모아 (coalescing) 반환한 것으로 간주한다.
Piggybacking ACK
TCP는 일반적으로 양방향 통신을 하고, 어플리케이션의 작성 방법으로 '클라이언트'에서 '서버'에 '요청'을 보내고, '서버'에서 '클라이언트'로 '응답'을 하는 것이 보통이다. 즉, 패킷은 번갈아 왔다 갔다 한다. 그래서 ACK 는 전용 패킷으로 보내는 것이 아니라, 수신측에서 응답 데이터를 실은 패킷에 합승하는 형태로 송신 한다 (이것을 '편승(piggy-back)'으로 표현한다). 이에 따라 ACK 만으로 구성된 패킷이 흘러다니는 낭비를 없애고 있다. 하지만, 패킷이 단방향으로 밖에 흐르지 않는 상태가 계속 되면, 페이로드가 0 바이트인 패킷을 사용해 ACK를 보내는 것이 된다.
PSN에 따라 바이트 스트림 내에 4G바이트 윈도우가 가능하지만, 슬라이딩 윈도우의 제한으로 한번에 보내는 것은 1G바이트까지로 되어 있다. TCP에서는 PSN이 만든 서클의 1/4이 수신 영역이고, 그 이외는 과거에 보낸 패킷이 지연되어 도착한 것이라고 판단한다.
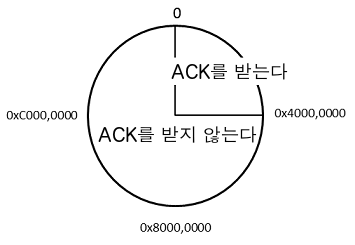
11.2 재전송 제어
InfiniBand의 신뢰성 있는 서비스도 Packet Sequence Number (PSN)을 이용한다. 명칭은 TCP와 같지만, 여기에서는 바이트 위치가 아니라 패킷을 세는 카운터이다. 또한 24바이트 크기 로 되어있다.
InfiniBand도 패킷의 MTU를 갖고 있으며, 256/512/1024/2048/4096 바이트 중 한가지가 된다. 이 MTU는 패킷 헤더 등을 제거한 페이로드 부분의 사이즈를 의미하는 것으로 InfiniBand의 하나의 패킷은 최대 4KB 데이터를 보내는 것이 가능하다. 따라서, InfiniBand의 PSN이 만든 서클은 1바퀴가 64GB에 해당하게 된다.
InfiniBand에는 TCP의 슬라이딩 윈도우에 해당하는 것이 없다. 그 대신 송신측은 송신 완료를 확인할 수 있는 최신 PSN을 기점으로 보고, 서클의 절반보다 앞에 있는 PSN을 가진 ACK가 되돌아 오는 경우, 그것을 과거에 보낸 패킷이 지연되어 도착한 것으로 판단한다. 즉, MTU=4KB 계산으로 하면32GB의 슬라이딩 윈도우를 갖고 있는 것으로 간주할 수 있다.
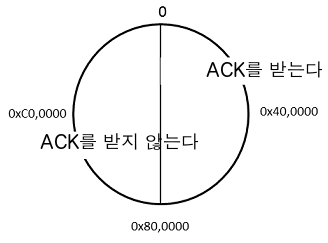
InfiniBand에는 piggy-back이 아니라, ACK 타입을 가진 전용 패킷을 돌려 보낼 필요가 있다. Coalescing ACK는 존재한다.
11.3 혼잡제어
InfiniBand에는 먼저 인접해 있는 스위치간에 동작하는 데이터링크 계층의 혼잡 제어가 있다. 이것은 Flow Control Packet이라는 특수한 교환을 하는 것으로, 서로의 패킷의 버퍼 사이즈와 비어있는 용량을 통지하는 메커니즘이다. InfiniBand는 12비트의 크래딧(카운터)으로 버퍼 사이즈의 절대값을 나타내는 점이 다른 시스템과 다른 점이다.
또 한가지, 이것은 RC 서비스뿐이지만 end-to-end 혼잡제어가 있다. 6.7에서 쓴 것과 같이 SEND 오퍼레이션과 RDMA WRITE with Immediate 오퍼레이션은 수신측이 RQ에 Receive WR을 쌓지 않으면 안된다. 만약 RQ가 비면, RNR NAK가 반환되고, 송신측이 일정 시간 멈춰 버린다. 이것을 막기 위해 SEND 오퍼레이션과 RDMA WRITE with Immediate 오퍼레이션이 성공한 때의 ACK에는 RQ의 WQE의 잔량을 표시하는 크래딧을 5비트의 필드에 포함한다. 송신측은 이 필드 정보에 근거하여, 이후의 SEND 오퍼레이션, RDMA WRITE with Immediate 오퍼레이션의 발행량을 조정한다.
이 end-to-end 혼잡제어는 SRQ를 이용하고 있는 경우에는 유효하지 않다. 또한 Immediate 없는 RDMA WRITE 오퍼레이션, RDMA READ 오퍼레이션, ATOMIC 오퍼레이션에서는 효과를 발휘하지 못한다.
12. 보호 메커니즘
12.1 RDMA를 위한 보호 메커니즘
RDMA WRITE나 RDMA READ는 리모트에서 메모리 어드레스 공간을 읽고 쓰는 오퍼레이션이지만, 이것이 통신 상대의 LID, QP 번호, PSN이 아는 것만으로 되어 버리는 것은 위험하다. 이것을 방지하기 위한 몇가지 보호 메커니즘이 존재한다.
먼저 프로텍션 도메인(protection Domain)이 있다. 지금까지의 설명에서는 없었지만, InfiniBand Verbs를 사용하는 프로세스는 내부에 프로텍션 도메인이라고 불리는 영역을 여러개 만들 수 있고, QP나 Memory Region은 프로텍션 도메인 내에 만들 수 있다. 따라서, QP가 소속한 프로텍션 도메인을 구분해 사용하는 것으로, 외부로부터의 RDMA액세스 범위를 제한할 수 있다.
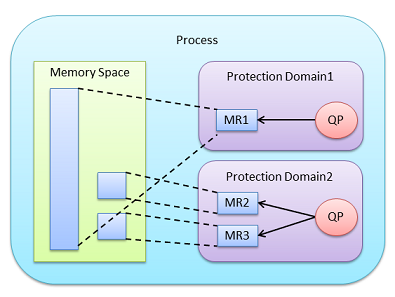
또 한가지 메커니즘인 Memory Region은 그것을 작성한 때에 HCA가 Remote Key (R_Key)라는 32비트 값을 생성한다. RDMA READ나 RDMA WRITE는 이 R_KEY를 Send WR 내에 포함해 통신을 하며, 값이 일치하지 않는 경우는 리모트에서 에러로 감지할 수 있다.
12.2 UD서비스를 위한 보호 메커니즘
UD 서비스는 다대다 통신이며 LID와 QP 번호에 의해 수신지를 결정하지만, 그것만으로는 누구라도 메시지를 송신할 수 있게 된다. 이것을 막기 위해UD QP에는 Queue Key (Q_Key)를 설정할 수 있고, SEND 오퍼레이션의 Send WR에는 수신처 UD의 Q_Key를 설정한다. 메시지에 포함된 Q_Key와 리모트(수신측) QP의 Q_Key가 일치하지 않는 경우는 보고하지 않고 파기(silently drop)되므로, Q_Key를 알지 못하면 통신할 수 없다.
Q_Key는 32비트 크기가 있지만, 사용자 프로그램은 최상위 비트를 0으로한 값(0x0000,0000〜0x7FFF,FFFF)을 사용하는 것이 가능하다. 최상위 비트를 1로한 값(0x8000,0000〜0xFFFFF,FFFFF)는 시스템이나 HCA가 고유 정보를 설정하기 위해 사용하므로, 사용자 프로그램은 사용해서는 안된다.
12.3 Partition
InfiniBand에는 서브넷 상에 Partition이라 불리는 레이어를 만들 수 있다. Partition은 16비트 Partition Key (P_Key)로 식별되며, HCA포트를 지정 partition에 참가시키는 것도 가능하다. 포트에는 P_Key를 저장하는 표(Partition Key Table)가 있어, 여러 개의 partition에 동시에 속하는 것이 가능하다. Partition Key Table 항목 수는 max_pkeys로 보고되고, Mellanox ConnectX-3의 경우 128개로 되어 있다.
P_Key 중에서 0xFFFF는 Default Parition Key이며, Partition Key Table의 0번째 항목은 반드시 0xFFFF로 설정된다. 즉, 서브넷 내의 모든 노드가 참가하는 partition이 반드시 하나는 있다는 것이다. Partition Key Table을 설정하는 것은 Subnet Manager이며, 이 설정에는 SMP를 사용한다. QP0는 partition에 소속되지않으며, 검사없이 전송된다.
실제로 Partition은 QP마다 적용된다. 사용자 프로그램은 QP를 Partition Key Table 중 어떤 하나를 설정할 수 있다. 이후, 이 QP에서 송신된 메시지의 패킷 내에는 P_Key가 포함된다. 수신처의 QP가 같은 partition에 속해(같은P_Key값을 가짐)있지 않으면, 패킷은 폐기 된다.
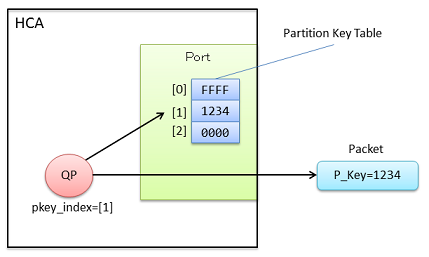
InfiniBand의 Partition과 이더넷의 VLAN은 실제로 다른 메커니즘이다. 이더넷의 VLAN은 네트워크를 완전히 분리하고, 다른 VLAND의 패킷을 차단할 수 있다. 따라서, 하나의 로컬 네트워크를 고객으로 나눠 사용하는 등의 이용이 가능하다.
한편, InfiniBand의 partition에 의한 서브넷의 분할은 불충분하다. 서브넷 내에서 공통 partition이 존재하고, SMP를 자기 자신에게 던지는 것으로P_Key를 바꿔 쓰는 것도 가능하게 되어 있어, 보안 수준이 낮다. 실제로 IPoIB의 VLAN 구현 등에 이용 된다.
1. 역자주) 直結 ↩
2. 역자주) https://ko.wikipedia.org/wiki/여유도 ↩
3. 역자주) https://ko.wikipedia.org/wiki/네트워크_토폴로지 Fully connected mesh topology.フルメッシュ ↩
4. 역자주) 符牒 - (기억해 두기 위한) 표시 ↩